$Id: fuzzyml-summary.html,v 1.7 1999/04/26 13:17:27 kev Exp kev $
Fuzzy logic has had a great deal of success where it has been applied in the real world, and is often touted as a means of making machines smarter. However, for the most part, fuzzy logic has actually been used in control systems as a way of providing more human-like behaviour. For example, many household appliances (notably whitegoods such as washing machines and refrigerators) now contain fuzzy control systems that allow the machine to adjust to the specific circumstances currently presented to it, as with the fan example in the previous paragraph. While this does improve the machines and their behaviour, it isn't really an advance in the areas of general intelligence on arbitrary domains and machine learning. Only (relatively) recently is the area of fuzzy machine learning being developed, with the most popular approach being fuzzy neural networks (often abbreviated to simply neuro-fuzzy) to allow machine intelligences to learn from empirical data and experiences.
The project will comprise a series of controlled experiments on the performance of various algorithms on a standardised set of datasets (most likely from the USI repository). The performance is how many correct conclusions an algorithm draws based on given data and conclusions. There are three different categories of algorithms that will be examined. First, some standard ML algorithms, second, some hand-crafted fuzzy rules based on a human's examination of the dataset, and third, if time permits, some neuro-fuzzy ML algorithms. It is hoped that at least two different datasets will be used, with as many as five datasets (depending on availability of dataset results and implementations).
Where possible, existing results on the datasets will be used (ie. as obtained by researchers, probably the implementors of algorithms). If results are not available, implementations will be sourced to process the datasets, with preference to those that require the smallest amount of coding (as the point of the project is to analyse the results, not to construct the system). For the standard ML and neuro-fuzzy ML algorithms, this will require finding complete implementations of the ML algorithms that can be run on the datasets; for the hand-crafted fuzzy rules this will require finding fuzzy logic toolkits that can be used as a basis for constructing the fuzzy rules that can be used to process the datasets. When constructing the fuzzy rules, the human will be actively encouraged to take advantage of all human thought processes and percepts through the use of tools helping to reveal the hidden internal structure of the dataset, such as scientific visualisation software.
Another outcome will be the effectiveness and suitability of fuzzy logic methods and ideologies with respect to machine learning. Again, this will be obtained from a comparison of the hand-crafted fuzzy logic rules and the ML algorithms. In addition, if time permits, the results of some fuzzy ML algorithms (most notably neuro-fuzzy techniques) on the standardised datasets may be compared to the hand-crafted fuzzy rules and standard ML algorithms.
Also, one philosophical question which may be addressed is that of the existance of an impervious gap between human and machine intelligence. Put simply, can the human brain see, identify and interpret patterns in data (constructed or sensory), and subsequently draw conclusions and generalisations, in a way that machines cannot? And if so, would machines need to make a kind of "quantum leap" into some form of consciousness in order to be as effective in these tasks as humans?
The bulk of the project will be the construction of the fuzzy rules for each of the datasets. The rules will be constructed in a suitable fuzzy toolkit to allow the rules to be aptly expressed using fuzzy logic notions and human-like expressions, while still allowing them to be run over a dataset to produce predictions. Several tools will be utilised in order to analyse the datasets and construct the rules, most notably scientific visualisation software such as AVS and IBM Data Explorer (IBM DX). Other investigations may look at properties such as the statistical makeup of the dataset or sorting the dataset by different attributes in order to attempt to locate trends or constants (or almost-constants) in the dataset.
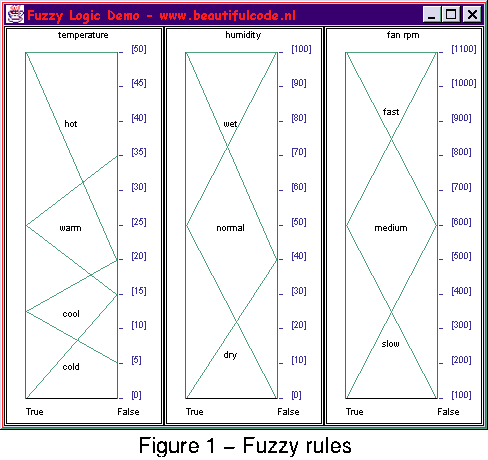
The problem with these kinds of datasets is that they contain many variables, meaning that the problem is in a high dimensional space. A problem with two variables has the problem space of a square, three variables a cube, and from four variables onwards simple visualisation becomes a problem. Fuzzy rules are usually drawn in a fashion similar to those in Figure 1, and ultimately this is what the hand-crafted fuzzy rules will look like. However, arriving at those pictures will not be as easy for a lot of variables as it is for three variables (as in Figure 1), and this is why a more advanced analysis of the datasets will be needed.
Finally, an environment such as Delve (Data for Evaluating Learning in Valid Experiments, http://www.cs.utoronto.ca/~delve/) may be used to ensure that all the tests and datasets are standardised and well documented. Further, this would allow the extension of comparing the results in a consistent fashion to other learning methods that use Delve.